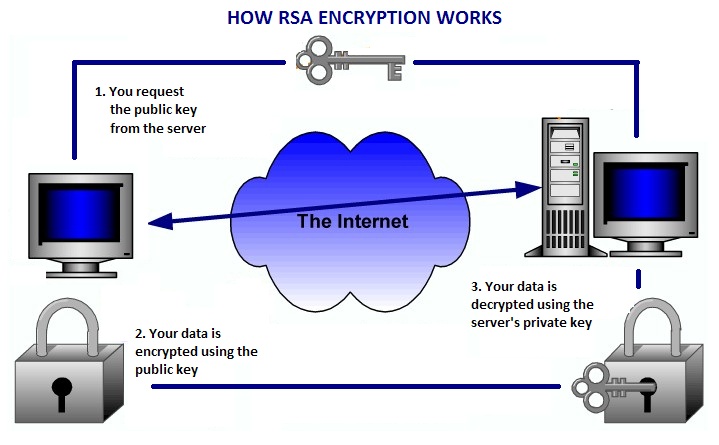
And God said let their be spam. And ever since, there was spam. It seems like spam these days never ends. It is a constant battle with no winners or losers. Sort of like the war on terrorism. But that’s a topic for another day. However, we are not all doomed. At least for now, thanks to Thomas Bayes and his bayesian spam filtering. So how does this bayes theorem work anyways? Let’s say a given spam has the word ‘free’ in it. We all know nothing is free these days. Bayes theorem states the following:
P(A|B) = [ P(B|A) * P(A) ] / P(B)
Read as: The probability of A given B is equal to the probability of B given A times the probability of A divided by the probability of B.
In our case lets specialize this formula to spam:
P(S|W) = [ P(W|S) * P(S) ] / [P(W|S) * P(S)] + [P(W|H) * P(H)]
Looks complicated I know. But it really isn’t.
- P(S|W) is the probability that a message is a spam, knowing that the word “free” is in it.
- P(S) is the overall probability that any given message is spam.
- P(W|S) is the probability that the word “free” appears in spam messages.
- P(H) is the overall probability that any given message is not spam (aka ham).
- P(W|H) is the probability that the word “free” appears in ham messages.

But it does get complicated because we are dealing with multiple words. For multiple words the formula gets a little complicated.
P(S) = p(w1) * p(w2) * … / (p(w1) * p(w2)* … ) + (q(w1) * q(w2) * …)
Now that we have the details taken care of lets look at the code to a simple bayesian spam filter written in c++.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 | /*************************************************************************** * Program: * Bayesian Spam Filter * * Author: * Don Page * * Summary: * This program reads in a hypothetical list of words and frequencies * in both spam and ham e-mail messages and then uses Bayesian * inference to determine whether hypothetical e-mail messages are spam * or not. The program's judgment may be wrong in some cases, but such * is the case with industrial-strength spam filters as well. ******************************************************************************/ #include <iostream> #include <fstream> #include <string> #include <set> #include <ctype.h> using namespace std; class Words { private: int numWords; string words[200]; float spam[200]; float ham[200]; public: Words(); int getIndex(string pWord); float getSpam(string pWord); float getHam(string pWord); void insertWord(string pWord, float pSpam, float pHam); }; /****************************************************************************** * Default Constructor ******************************************************************************/ Words::Words() { numWords = 0; } /****************************************************************************** * INPUT: pWord - Word to insert * pSpam - Probability of spam * pHam - Probability of ham ******************************************************************************/ void Words::insertWord(string pWord, float pSpam, float pHam) { words[numWords] = pWord; spam[numWords] = pSpam; ham[numWords] = pHam; numWords++; } /****************************************************************************** * Read words and their probabilities of being ham and spam from file ******************************************************************************/ Words* readWords(ifstream& words) { string word; float spam; float ham; Words* myWords = new Words(); while(!words.eof()) { words >> word; words >> spam; words >> ham; myWords->insertWord(word, spam, ham); } return myWords; } /****************************************************************************** * Checks if word is inside spam list. Returns prob of spam or -1 if !found ******************************************************************************/ float Words::getSpam(string pWord) { int index = getIndex(pWord); if (index != -1) // found return spam[index]; else return -1.0; // not found } /****************************************************************************** * Checks if word is inside ham list. Returns prob of ham or -1 if !found ******************************************************************************/ float Words::getHam(string pWord) { int index = getIndex(pWord); if (index != -1) // found return ham[index]; else return -1.0; // not found } /****************************************************************************** * Finds a given word inside list of words. Returns -1 if not found ******************************************************************************/ int Words::getIndex(string pWord) { //Convert string to lowercase for (int i = 0; i < pWord.length(); i++) pWord[i] = tolower(pWord[i]); int i = 0; for (; words[i] != pWord && i < numWords; i++); // Check to see if word was found if (words[i] == pWord) return i; else return -1; } /****************************************************************************** * Process each message using Bayes theorem to calculate if message is Spam * or Ham. See below for Bayes thereom on multiple words. * P(S) = p(w1) * p(w2) * ... / (p(w1) * p(w2)* ... ) + (q(w1) * q(w2) * ...) ******************************************************************************/ void processMessages(Words* words, ifstream& messages) { int message = 1; string word; float probSpam; float probHam; string cleanWord = ""; messages >> word; while(!messages.eof()) { messages >> word; // First word is message probSpam = 0.0; probHam = 0.0; while (word != "MESSAGE" && !messages.eof()) // New message { //Parse word for (int i = 0; i < word.length(); i++) { if (isalpha(word[i])) { cleanWord += word[i]; } if (!isalpha(word[i]) || i == word.length() - 1) // Check cleanWord if it's spam { if (cleanWord.length() > 0) { float temp = words->getSpam(cleanWord); if (temp > -1.0) // If Spam Calculate new probSpam probSpam != 0.0 ? probSpam *= temp : probSpam = temp; temp = words->getHam(cleanWord); if (temp > -1.0) // If Ham Calculate new probHam probHam != 0.0 ? probHam *= temp : probHam = temp; cleanWord = ""; } } }// for messages >> word; }// while // Should we reject message? float threshold = probSpam / (probSpam + probHam); cout << "Message " << message << " has a " << threshold << " probability of being spam, "; if (threshold < .9) // Accept cout << "so let it through.\n\n"; else // Reject cout << "so reject it.\n\n"; message++; } return; } /****************************************************************************** * Opens two input files, words.txt and messages.txt, reads in the words and * their spam/ham frequencies, and with that data processes the messages * to determine if they (the messages) are spam or not. * * DO NOT MODIFY ANYTHING BELOW THIS LINE! ******************************************************************************/ int main(int argc, const char* argv[]) { // Set decimal precision for output. cout.setf(ios::fixed); cout.setf(ios::showpoint); cout.precision(2); if (argc < 3) { cerr << "Usage: " << argv[0] << " [words file] [messages file]\n"; exit(1); } ifstream words(argv[1]); ifstream messages(argv[2]); if (words.fail() || messages.fail()) { cerr << "File opening failed.\n"; exit(1); } processMessages(readWords(words), messages); return 0; } |